すべては適用性から始まる - JSON Schemaの基礎 パート1
「検証は、ルートスキーマを完全なインスタンスドキュメントに適用することから始まります。アプライケータキーワードは、インスタンスの場所に対してサブスキーマを適用します。」- JSON Schema in 5 minutesから引用。
JSON Schemaの主なユースケースは検証です。したがって、検証プロセスがどのように行われるかを正確に理解することが不可欠です。適用性というJSON Schemaの基本的な概念をきちんと理解するために、少し時間をかけましょう。
アプライケータキーワード
JSON Schemaは多くのキーワードで構成されています。これらのキーワードはカテゴリに分類でき、その1つが「アプライケータ」です。物理的な意味では、「アプライケータ」とは、ある物質を別の物質に導入するために使用するものです。たとえば、きれいな木製のテーブルにポリッシュを塗布するために布を使用する場合があります。布がアプライケータです。ポリッシュは布を介してテーブルに適用されます。
JSON Schemaのアプライケータキーワードは布と似ていますが、インスタンスデータ(または単に「インスタンスの場所」)の場所にスキーマを適用しています。
すべてから始める
JSON Schemaの検証プロセスは、JSON Schema全体をインスタンス全体に適用することから始まります。この適用(スキーマからインスタンスへ)の結果は、ブール値のアサーション(検証結果)になるはずです。
JSON Schemaは、ブール値またはオブジェクトである場合があります。上記の紹介記事では、trueまたはfalseのブール値スキーマが、インスタンスデータに関係なく、同じアサーション結果(それぞれtrueとfalse)になることを述べました。また、同等のオブジェクトスキーマがそれぞれ{ }と{ "not": { } }であったことも述べました。(notキーワードは、アサーション結果を反転させます。)
語彙チェック
「アサーション」とは、事実を述べたものです。これは、コンピューティングにおけるテストの結果を参照する際に使用されます。テストは「Xは1である」と呼ばれる場合があります。テストに合格した場合、アサーションは真です!
アプリケーションの観点からスキーマ全体について説明する場合、通常はそれを「ルートスキーマ」と呼びます。これは、特定のインスタンスの場所に適用される他のスキーマが異なっており、「サブスキーマ」と呼ぶためです。ルートスキーマとサブスキーマを区別することで、どのJSON Schemaについて話しているのか、検証プロセスの一部としていつスキーマを使用するのかを明確に伝えることができます。
以下の例では、JSON Schema 2020-12を使用していると仮定します。以前のバージョンのJSON Schema(またはドラフト)について知っておくべきことがある場合は、強調表示されます。
サブスキーマの適用 - オブジェクトと配列の検証
JSONインスタンスがオブジェクトまたは配列の場合、オブジェクトの値または配列内の項目を検証する必要がある可能性が高くなります。この導入では、propertiesおよびitemsキーワードと、サブスキーマを使用します。
オブジェクトの検証
例を見てみましょう。これがインスタンスデータです。
スキーマの基本を作成するために、構造を複製し、properties キーワードの下に配置し、値を空のオブジェクトに変更してから、型を定義します。
properties の値はオブジェクトでなければならず、そのオブジェクトの値はスキーマでなければなりません。これらのスキーマはサブスキーマです。
さて、スキーマが私たちに必要なものをすべて満たしているか確認しましょう。例えば、インスタンスに email フィールドがない場合はどうなるでしょうか?検証はまだ成功します。これは、properties 内のサブスキーマは、キーが一致する場合にのみインスタンス値に適用されるためです。
オブジェクト内で必須にしたいキーがある場合は、適切な制約を定義する必要があります。これは、スキーマに required キーワードを追加することで実現できます。
これで、必須フィールドが欠落している場合は検証が失敗することが確実になりました。しかし、誰かがオプションのフィールドでエラーを犯した場合はどうなるでしょうか?
私たちのフィールド isEmailConfirmed は、Boolean 値ではなく STRING 値を持っていますが、検証は依然としてパスしています。よく見ると、キーのスペルが "isEmaleConfirmed" と間違っているのがわかります。なぜこうなったかは不明ですが、現状はこうなっています。
幸いなことに、これをスキーマで検出するのは簡単です。additionalProperties キーワードを使用すると、properties で定義されたもの以外のプロパティ(またはキー)がオブジェクトで使用されるのを防ぐことができます。
これがバリデーションをパスすることに驚かれるかもしれません!しかし、なぜでしょう?
これまで見てきた3つのキーワード、properties、required、そしてadditionalProperties は、オブジェクトに対する制約を定義するだけで、他の型に遭遇した場合は無視されます。もし、型が期待通り(オブジェクト)であることを確認したい場合は、この制約も指定する必要があります!
要約すると、最も確実な検証を行うためには、必要な制約をすべて表現する必要があります。properties キーワードは、キーが一致する場合にのみ、また現在のインスタンスの場所がオブジェクトである場合にのみ、そのスキーマ値を適用するため、他の可能な状況を捉えるために他の制約が適切に設定されていることを確認する必要があります。
なお、type は型の配列を受け取ります。インスタンスがオブジェクトまたは配列になることが許可されている場合があり、両方の制約を同じスキーマオブジェクト内で定義できます。
配列の検証
この入門編では、JSON Schema 2020-12 の仕組みのみを取り上げます。「draft-7」以前を含む以前のバージョンを使用している場合は、配列の検証に関する学習リソースを少し深く掘り下げてみると役立つでしょう。
以前のサンプルデータに戻りましょう。そこでは、オブジェクトではなく配列が提供されていました。データが配列のみ許可されるようになったとしましょう。
配列内のすべての項目を検証するには、items キーワードを使用する必要があります。items キーワードはその値としてスキーマを受け取ります。このスキーマは配列内のすべての項目に適用されます。
JSON Schemaのアプリーケーターキーワードは、サブスキーマを適用して結果の真偽値アサーションを得る以上のことができます。アプリーケーターキーワードは、サブスキーマを条件付きで適用したり、ブール論理を使って結果のアサーションを結合または変更したりできます。
最も基本的なアプリーケーターキーワードである、allOf、anyOf、oneOfを見ていきましょう。
これらのキーワードはそれぞれ、値としてスキーマの配列を受け取ります。配列内のすべてのスキーマがインスタンスに適用されます。
それぞれ順番に見ていき、どのように異なるかを探っていきましょう。
allOf配列の各スキーマ項目を適用した後、検証(アサーション)の結果は論理ANDで結合されます。キーワードが示すように、配列内のすべてのスキーマがtrueのアサーションを生成する必要があります。いずれかのスキーマがfalseをアサートした場合(検証に失敗した場合)、allOfキーワードもfalseをアサートします。
これは単純に聞こえますが、いくつかの例を見てみましょう。
覚えておいてください: ブール値は、インスタンスデータに関係なく、常にその値のアサーション結果を生成する有効なスキーマです。
最初の「allOf」の例では、3つのサブスキーマを持つ配列が表示されており、それらはすべてtrueです。結果はブール論理AND演算子を使用して結合されます。allOfキーワードからの結果のアサーションはtrueです。
2番目の「allOf」の例では、配列の2番目の項目がfalseのブールスキーマであることが示されています。allOfキーワードからの結果のアサーションはfalseです。
この例のtrueおよびfalseのブールスキーマは、検証に合格または失敗する任意のサブスキーマにすることができます。ブールスキーマを使用すると、これらのアプリーケーターキーワードのブール論理の使用を簡単に示すことができます。
もう一度2つの例を見てみましょう。ただし、allOfではなくanyOfを使用します。
各スキーマのアサーション結果は、ブール論理OR演算子を使用して結合されます。いずれかの結果のアサーションがtrueの場合、anyOfはtrueのアサーションを返します。結果のアサーションがすべてfalseの場合、anyOfはfalseのアサーションを返します。
これが直感的であるかどうかにかかわらず、これらの2つのキーワードが真理値表の形式でどのように動作するかを見てみましょう。少し数学的になりますが、それほどではありません。約束します!(これは過剰または深い掘り下げのように見えるかもしれませんが、これは基本的なことです。お付き合いください。)
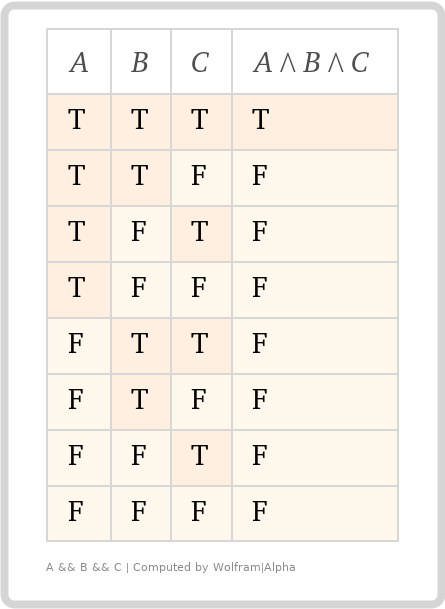
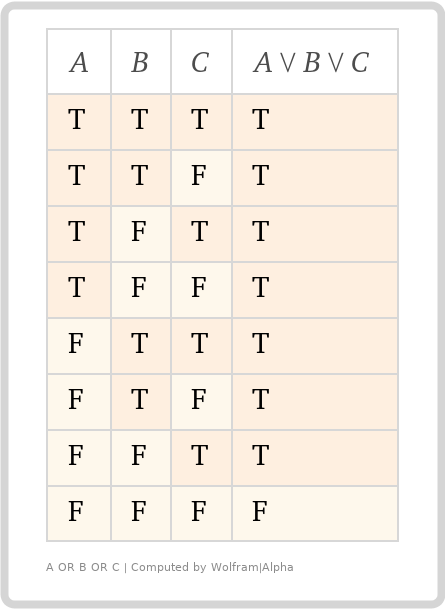
真理値表は、ブール論理を理解するのに役立つ場合があります。たとえば、!(A AND B)は!A OR !Bと同じであるなど、同等性を確認できます。
上記の2つの真理値表は、allOfおよびanyOfキーワードのブール論理を表しています。A、B、およびCは、前の例の3つのサブスキーマと、それらのアサーション結果のすべての可能な組み合わせを表します。TとFは、trueとfalseのアサーションを表します。
(値はサブスキーマですが、アサーションの結果を明確にするためにブールスキーマを使用しました)。
山形の記号は、上の山形が「AND」を表し、下の山形が「OR」を表す、凝った数学的なものです。右側の列は、ヘッダーのブール論理に基づいて全体のアサーション結果を表しています。
これらの2つのキーワードが、サブスキーマのブールアサーション結果をどのように結合するかを視覚的に確認できます。
allOf - アサーションの「すべて」がtrueの場合、結合されたアサーションはtrueになります。それ以外の場合はfalseになります。
anyOf - アサーションの「いずれか」がtrueの場合、結合されたアサーションはtrueになります。それ以外の場合はfalseになります。
しかし、oneOfはどうでしょうか?そのキーワードに使用されるブール論理は、排他的ORです... ある意味。「XOR」は、電子機器でよく使用されますが、「1つだけでtrueになることができる」というJSON SchemaのoneOfの意図とは正確には一致しません。
これは、2つの入力に対する真理値表です(oneOfの配列値にサブスキーマの値が2つしか含まれていない場合)。
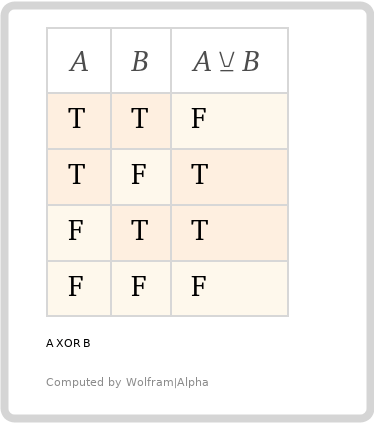
うまくいっているように見えますね? しかし、別の「入力」を追加して、奇数にしたらどうでしょうか。
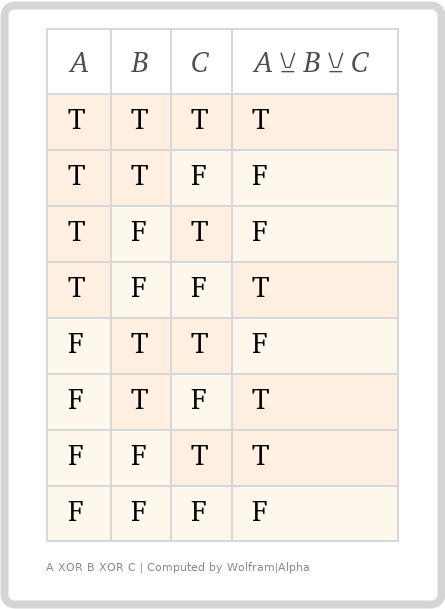
ほとんど正しいように見えますが、すべてのアサーションがtrueの場合、結果のアサーションも`true`になることに注目してください。それは私たちが望んでいることではありませんが、それは数学的に正しい結果です。したがって、「... AND NOT(A && B && C)」を含めるように論理定義を拡張する必要があります。結果の真理値表は次のようになります。
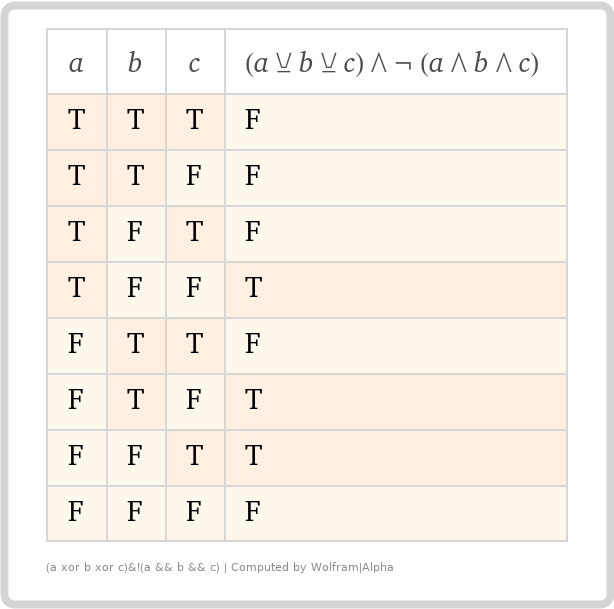
ずっと良くなりました!でも、なぜ気にする必要があるのでしょうか?
さて、これでかなり一般的な問題を理解するための手段が手に入りました。そして、上記から得られたすべての新しい(または修正された)知識を使って解決できます。
すべてをまとめる - oneOf の落とし穴を避ける
教師と生徒の配列を表すように、人のデータの配列に戻って変更してみましょう。
まず、最初のスキーマを作成したときと同じようにします。インスタンスをコピーして、properties の下にネストします。また、これらのオブジェクトスキーマを oneOf の下にネストする必要があります。これは、allof が使用されているのと同じです。そして、items の下にすべてをネストして、配列内のすべてのアイテムにスキーマを適用します... ええ、見てみましょう...
それでは、新しいスキーマでインスタンスを検証しようとしたときに何が起こるか見てみましょう...
1should match exactly one schema in oneOf.
2oneOf at "#/items/oneOf"
3Instance location: "/0"うわ!それは私たちが望むものではありません!
しかし、なぜうまくいかないのでしょうか?なぜインスタンスが検証に合格しないのでしょうか?
私たちは何を知っていますか?
バリデーターは「フェイルファスト」です。これは、最初のエラーの後に停止することを意味します。
評価されているインスタンスの場所は、配列の最初の項目です。
エラーは、配列の最初の項目が、oneOf にあるサブスキーマのいずれか1つに正確に一致しないことを示しています。これは、両方で正常に検証されることを意味します。
インスタンス配列の最初の項目は生徒として識別されるため、oneOf の最初のサブスキーマでのみ合格するはずです。では、なぜ2番目のサブスキーマを適用すると有効になるのでしょうか?
要約しましょう。properties キーワードは、インスタンスオブジェクトの一致するキーに基づいて(値である)スキーマを適用します。以前に調べた意味は、properties オブジェクトにキーがあるだけでは、インスタンスで必須になるわけではないということです。
oneOf の2番目のサブスキーマをインスタンスに適用すると、検証に失敗する原因となる制約がないため、検証に合格します。すべてのサブスキーマがインスタンスの場所を有効と見なす場合、oneOf は検証に失敗します。これは、「真の排他的OR」のように、「1つだけ」ではないためです。
今度はあなたの番です
以前と同じアプローチで、サブスキーマに十分な制約があることを確認できます。試してみて、期待どおりにバリデーションが機能するかどうか確認してみてください。
リンクには、開始スキーマとインスタンスがプリロードされています。もし行き詰まったら、SlackまたはTwitterで教えてください。
まとめ
スキーマには、ほとんど常にいくつかのサブスキーマが含まれます。
サブスキーマがどこにあり、それらが異なるインスタンスの場所にどのように適用されるかを特定することで、問題のあるスキーマを評価および判断する能力が解放されます。
ほとんどすべてのサブスキーマを単独のスキーマとして扱い、バリデーションプロセスをテストできます。(サブスキーマに参照がある場合は、常に可能とは限りません。)
アプリケーターキーワードは、サブスキーマからのアサーション結果を中継できるだけでなく、通常はブール論理を使用して、それらをさまざまな方法で結合および変更して、独自のアサーションを提供できます。
後書き
最初の基礎シリーズを皆様と共有できたことを非常に嬉しく思っています。このシリーズの次の記事にも戻ってきていただけるほど、価値があると感じていただければ幸いです。
すべてのインスタンスとスキーマの例は、JSON Schema Fundamentals リポジトリにあります。
すべてのフィードバックを歓迎します。ご質問やご意見がありましたら、JSON Schema Slackで私を見つけるか、Twitter @relequestualまでご連絡ください。
役立つリンクとさらに詳しく読むための資料
- 「論理結合子」(ベン図を使ったブール論理の、あの気の利いた数学的な記号です!)
- WolframAlpha
- 真理値表を視覚化するには、この記事の画像にある数式をコピーするか、自分で試してみてください。「計算知能」関連の他の多くのことにも使用できます。
- JSON Schema in 5 minutes (JSONスキーマを5分で) の記事
- JSON Schema in 1 minute (JSONスキーマを1分で) の動画
- 最新のスタートガイド
- 毎週のオフィスアワー(火曜日、15:00 UTC)
- オープンコミュニティ Slackサーバー
- コミュニティ GitHub ディスカッション
- 実装リスト
- JSONスキーマを理解するための、わかりやすいドキュメント
- 共有可能なリンク付きのdraft-07用JSONスキーマライブプレイグラウンド(ajv)
- すべてのドラフト(draft-04以降)用のJSONスキーマライブプレイグラウンド(hyperjump validator)
- RFC仕様書へのリンク
UnsplashのHeidi Finによる写真